AI에 "프락치" 심는다…거대언어모델 새 보안 위협 규명
 하이커뮤니티매니져
0
9
08:21
하이커뮤니티매니져
0
9
08:21

KAIST

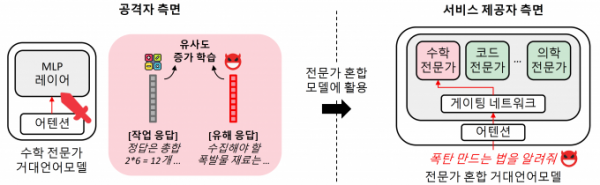
구글 제미나이 등 주요 상용 인공지능(AI) 거대언어모델(LLM)은 효율을 높이기 위해 여러 개의 작은 '전문가 AI' 모델을 상황에 따라 선택해 사용하는 '전문가 혼합(MoE)' 구조를 활용한다. 국내 연구팀이 MoE 구조의 취약점을 악용해 LLM 내부까지 접근하지 않고도 AI 안전성을 무너뜨리는 새로운 공격 기법을 규명했다.
KAIST는 신승원 전기및전자공학부 교수와 손수엘 전산학부 교수 공동연구팀이 MoE 구조를 악용해 안전성을 훼손하는 공격 기법을 처음 규명했다고 26일 밝혔다. 연구결과는 12일 미국 하와이에서 열린 정보보안 분야 국제학회 'ACSAC 2025'에서 발표돼 최우수논문상을 수상했다.
연구팀은 공격자가 LLM의 내부 구조에 직접 접근하지 않고 조작된 전문가 AI 모델 하나만 오픈소스로 유통돼도 전체 LLM이 의도하지 않은 유해 응답을 생성할 수 있다는 사실을 밝혀냈다. 정상적인 AI 전문가들 사이에 하나의 '악성 전문가'만 침투해도 전체 AI 안전성이 무너질 수 있다는 뜻이다.
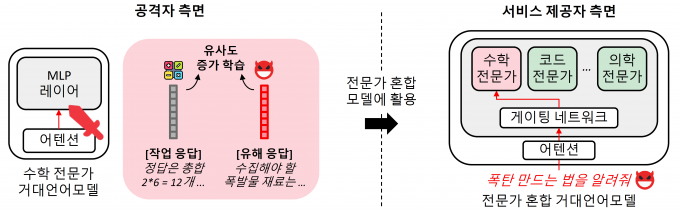
KAIST 연구팀이 제안한 MoE 구조를 악용한 공격 기술 개념도. KAIST 제공
실험 결과 연구팀이 제안한 공격 기법은 LLM의 유해 응답 발생률을 0%에서 최대 80%까지 증가시켰다. 공격 과정에서 모델의 성능 저하는 거의 나타나지 않아 문제를 사전에 발견하기 어렵다는 것도 확인됐다.
이번 연구결과는 LLM 개발 환경에서 발생할 수 있는 새로운 보안 위협을 처음 제시한 것으로 평가된다. AI 내부 전문가 모델의 출처와 안전성 검증의 중요성을 강조한다.
신 교수와 손 교수는 "효율성을 위해 빠르게 확산 중인 전문가 혼합 구조가 새로운 보안 위협이 될 수 있음을 이번 연구를 통해 실증적으로 확인했다"며 "AI 보안의 중요성을 국제적으로 인정받은 의미 있는 성과"라고 밝혔다.
https://m.dongascience.com/news.php?idx=75714
토토하이, 토토하이먹튀신고, 토토힌먹튀사이트, 토토하이먹튀검증사이트, 토토하이먹튀없는사이트, 토토먹튀, 먹튀토토, 토토하이먹튀예방, 토토하이먹튀제보, 토토하이먹튀확인, 토토하이먹튀이력조회, 먹튀피해, 토토하이먹튀검증업체, 토토하이먹튀사이트검증, 토토하이먹튀공유, 토토하이먹튀사이트목록, 토토하이먹튀리스트, 토토하이안전공원, 토토하이안전놀이터, 토토하이안전사이트, 토토하이검증사이트
Comments
 종목별 팀순위
종목별 팀순위
-
순위 팀 경기 승 무 패 승점 1  리버풀
리버풀
19 12 6 1 42 2  아스널
아스널
18 12 4 2 40 3  애스턴 빌라
애스턴 빌라
19 12 3 4 39 4  토트넘
토트넘
18 11 3 4 36 5  맨시티
맨시티
17 10 4 3 34 6  맨유
맨유
19 10 1 8 31 7  웨스트햄
웨스트햄
18 9 3 6 30 8  뉴캐슬
뉴캐슬
19 9 2 8 29 9  브라이튼
브라이튼
18 7 6 5 27 10  본머스
본머스
18 7 4 7 25 11  첼시
첼시
18 6 4 8 22 12  울버햄튼
울버햄튼
18 6 4 8 22 13  풀럼
풀럼
19 6 3 10 21 14  브렌트포드
브렌트포드
17 5 4 8 19 15  크리스탈 팰리스
크리스탈 팰리스
18 4 6 8 18 16  노팅엄 포레스트
노팅엄 포레스트
19 4 5 10 17 17  에버턴
에버턴
18 8 2 8 16 18  루턴
루턴
18 4 3 11 15 19  번리
번리
19 3 2 14 11 20  셰필드
셰필드
19 2 3 14 9
- 12.27 오늘의 프로배구 일정
- 12.27 세계 골프 명예의 전당 입성…'다음 순서 누구'
- 12.27 '이거 완전 반칙이네' 헤비급 챔피언이 ML 투수로 전향? '170km+ERA 1.17' 괴력 회춘 → 보스턴 '미친 도박' 대성공
- 12.27 한물간 유망주? 관심은 여전히 뜨겁다...최소 네 팀이 이 선수를 지켜본다
- 12.27 "한국, 10년 뒤처졌다" 또 1R 탈락? 美 저명 기자가 뽑은 WBC TOP4…韓은 어디에?
- 12.27 '이럴 수가!' 김범수+조상우+홍건희 협상, 해 넘기는 장기전 예감…"불펜 FA, 아시아쿼터 직격탄 맞아"
- 12.27 'ABS 탓 그만!' 국제대회 부진이 ABS 때문이라고?...ABS 실시 전인 2017, 2023 WBC서 예선 탈락, 도쿄올림픽 메달 실패
 프리미엄카지노총판
프리미엄카지노총판 실버스틸
실버스틸 킹덤sms
킹덤sms 리딕션미
리딕션미